У меня возникают проблемы с извлечением определенных страниц из моего PDF-файла, не вызывая нежелательных изменений в исходном файле.
Проблема
Задача заключается в выборе и извлечении конкретных страниц из обширного PDF-файла, что часто является сложной задачей без специализированных инструментов. Это становится еще сложнее, когда пытаешься собрать определенный контент для работы или отчетов. К тому же, существует риск нежелательных изменений в оригинальном PDF-файле, если извлечение не проводится должным образом. Поэтому требуется безопасный, эффективный и простой в использовании инструмент, который облегчит эту задачу, не ухудшая качество оригинального файла. Идеальный инструмент должен позволять пользователям легко выбирать и извлекать страницы, независимо от того, являются ли они студентами или профессиональными отчетчиками.
Снимки экрана
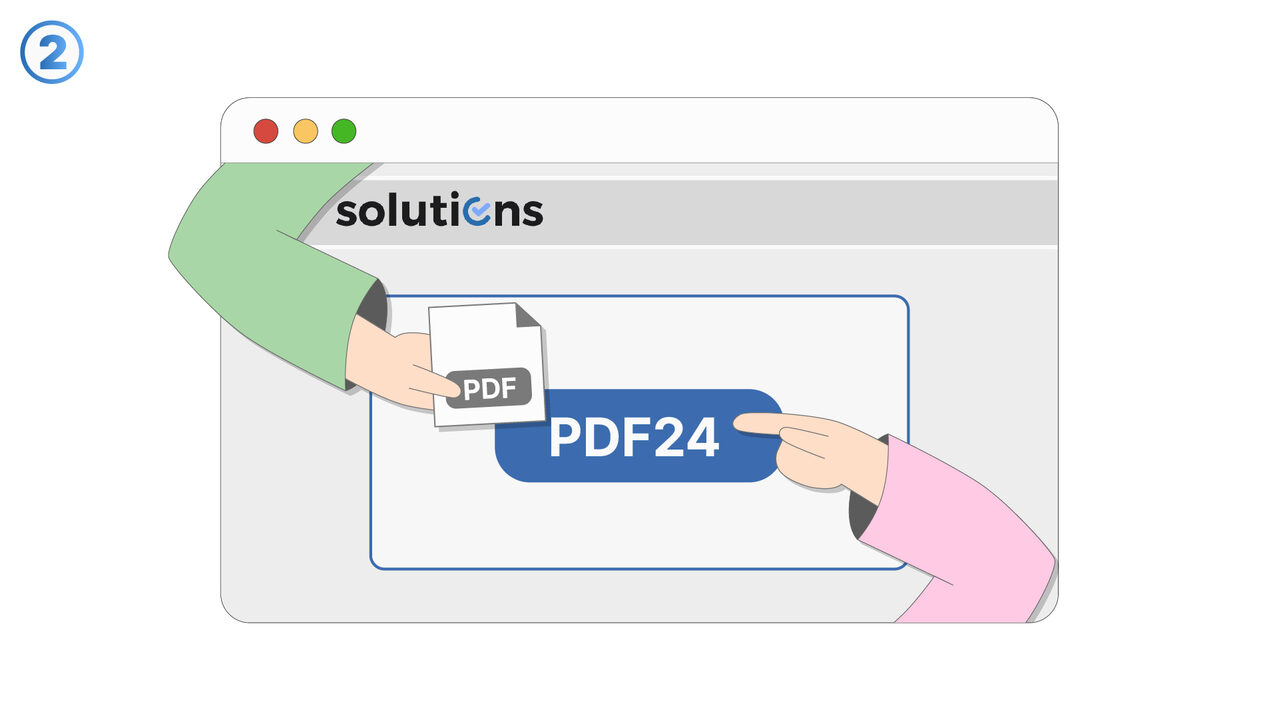
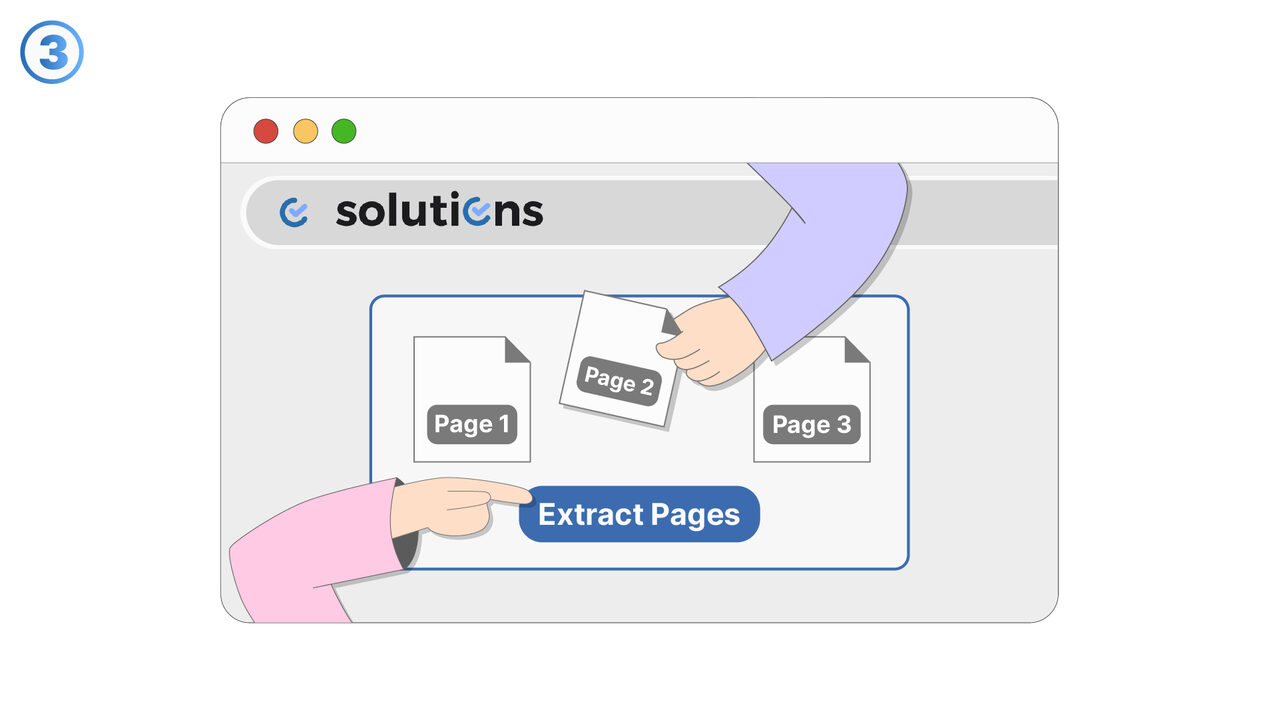
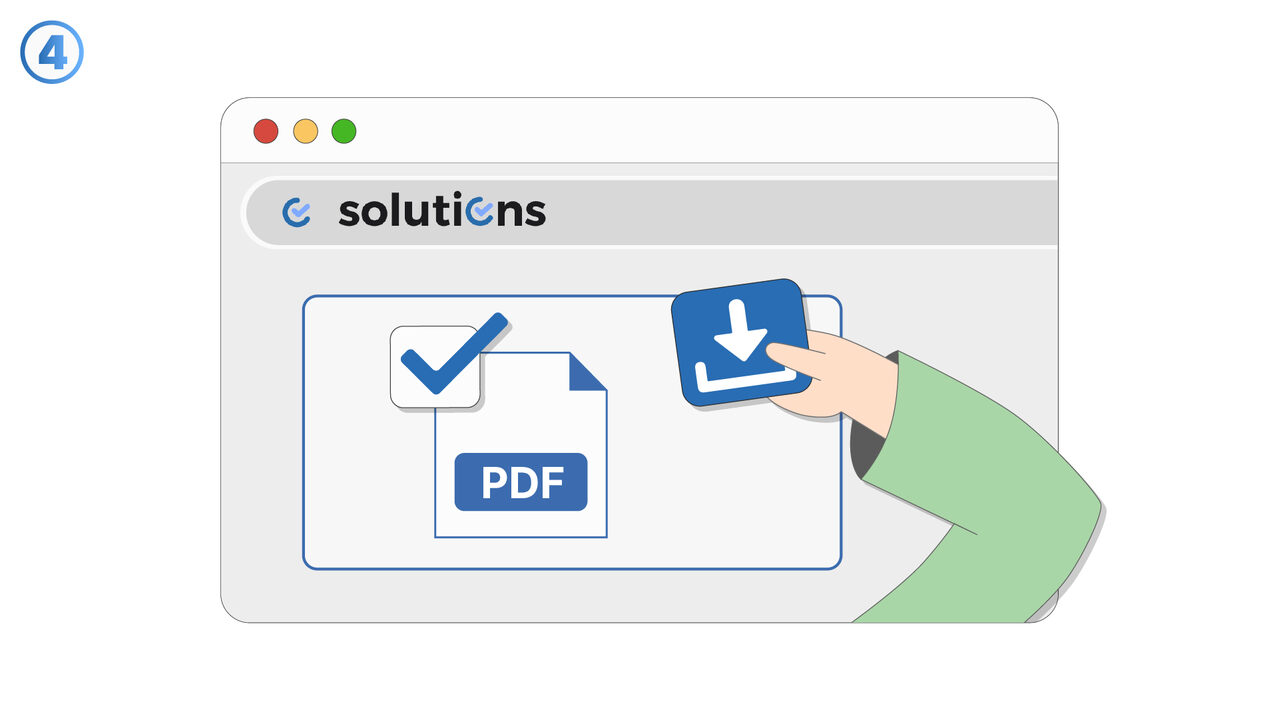
Попробуйте
Решение
Инструмент для извлечения страниц PDF предлагает простое и эффективное решение проблемы, описанной выше. Вы просто выбираете необходимые страницы в удобном пользовательском интерфейсе, и инструмент извлекает их из исходного файла, не изменяя его и не ухудшая качество. Неважно, студент вы или профессиональный репортер, извлечение конкретных страниц для вашей работы или отчетов становится детской игрой. Благодаря этому инструменту, вы можете отфильтровывать важное содержимое из обширных PDF-файлов и использовать его по своему усмотрению. Таким образом, исключается риск случайных изменений в оригинале и часто трудоемкий поиск конкретного содержимого внутри PDF. С помощью этого инструмента задача извлечения страниц становится значительно более эффективной и простой.
Внешний ресурс
https://tools.pdf24.org/en/extract-pdf-pages
Используйте этот инструмент как решение следующих проблем
- У меня возникают проблемы с извлечением конкретных страниц из файла PDF.
- При извлечении отдельных страниц из моего PDF-файла, я беспокоюсь о потере данных.
- У меня возникают проблемы при обработке очень больших PDF-файлов с помощью моего текущего инструмента для извлечения данных.
- Мне нужна программа, чтобы извлекать конкретные страницы из моих обширных PDF-файлов, не ухудшая качество исходного файла.
- У меня возникают проблемы с тратой времени на извлечение отдельных страниц из моих PDF-файлов.
- У меня возникают проблемы с извлечением конкретных страниц из моего обширного PDF-файла.
- Мне нужна возможность извлекать конкретные страницы из моих PDF-файлов, не теряя качества исходного файла.
- У меня возникают проблемы при начале использования инструмента для извлечения страниц PDF.
- У меня возникают проблемы при загрузке и распространении извлеченных страниц из моего PDF.
Знаете лучшее решение? Сообщите нам.
Если вы знаете инструмент или подход, который мог бы помочь решить проблему, которую мы ещё не рассматривали, мы будем рады об этом услышать.