Imam problema s digitalizacijom i pretraživošću štampanog teksta u mojim dokumentima i slikama.
Solved by Besplatni Online OCR
The Problem
Izazov leži u digitalizaciji i pretraživosti štampanog teksta iz dokumenata i slika. Ovaj proces može biti vremenski zahtjevan i mukotrpan, posebno kada dokumenti i slike sadrže veliku količinu informacija. Ručno unošenje podataka može dovesti do grešaka i često nije efikasno. Osim toga, može biti teško izvući štampani tekst iz dokumenata na različitim jezicima. Dakle, postavlja se pitanje jednostavne, brze i pouzdane metode za prepoznavanje i ekstrakciju teksta iz skeniranih dokumenata, PDF-a i slika.
Screenshots
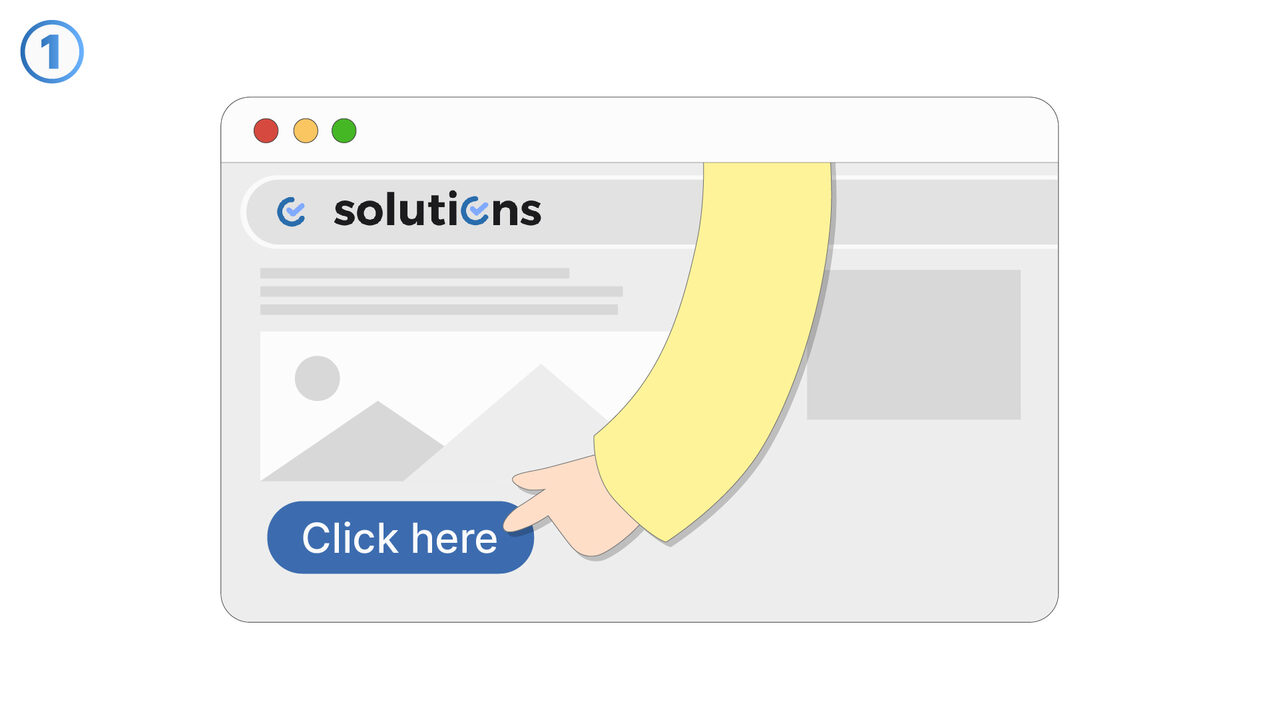
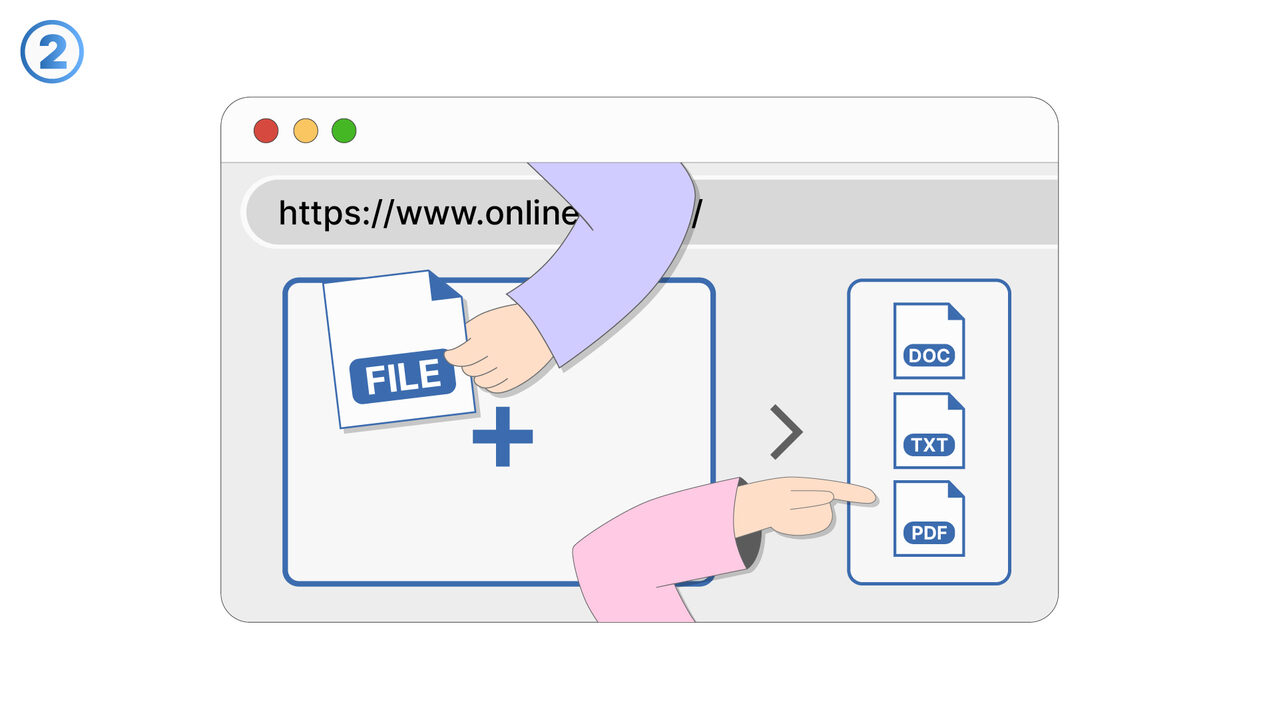
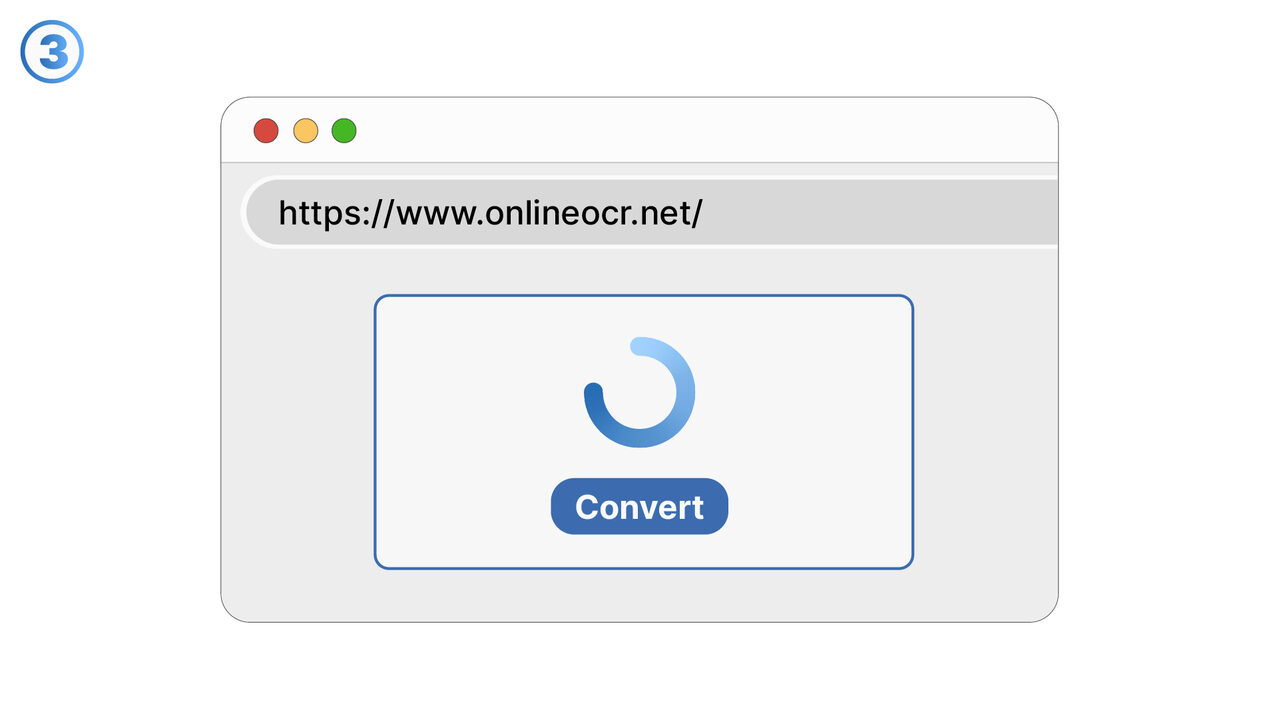
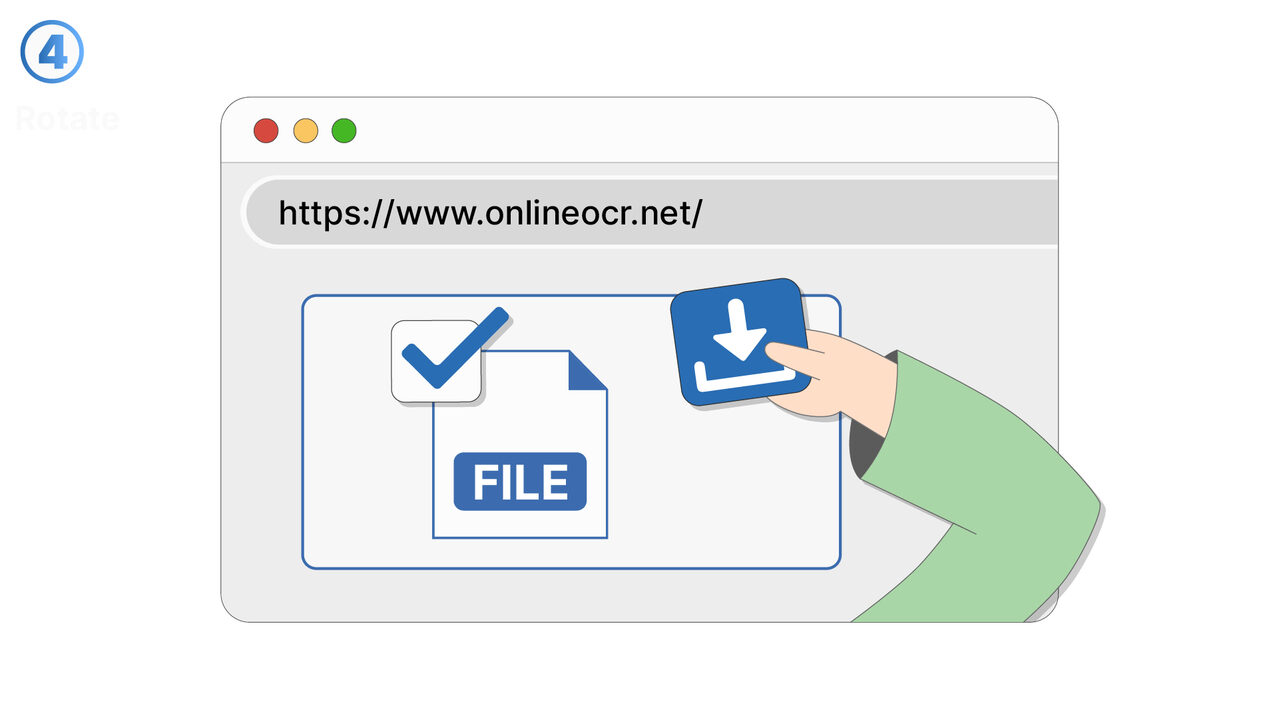
The Solution
Besplatni Online OCR revolucionira prepoznavanje teksta u skeniranim dokumentima, PDF-ovima i slikama. Koristeći svoju OCR tehnologiju, prepoznaje tekstove i pretvara ih u uređivane i pretražive formate poput DOC, TXT ili PDF. Istovremeno, smanjuje dugotrajan manuelni unos podataka i minimizira potencijalne izvore grešaka. Čak i dokumente i slike sa velikom količinom informacija ili na raznim jezicima, alat bez problema savladava. Kao rezultat toga, stvara se jednostavan, brz i pouzdan način za prepoznavanje i izdvajanje teksta. Ovaj alat je zbog toga idealan za sve koji redovno moraju raditi sa skenovima ili slikama i kojima su potrebne digitalne tekstualne informacije.
External Resource
https://www.onlineocr.net
Use this tool as a solution to the following problems
- Ne mogu uređivati tekst u mom skeniranom dokumentu.
- Ne mogu pretraživati tekst u PDF dokumentu i potrebno mi je rješenje za to.
- Borim se sa pretvaranjem skeniranih i odštampanih tekstova u uređivani format.
- Imam poteškoća u ekstrahovanju teksta iz skeniranih dokumenata i slika i pretvaranju u uređiv format.
- Moram pretvoriti skenirana dokumenta i slike na više jezika u uređivani tekst.
- Treba mi jednostavan i brz način za izvlačenje tekstualnih informacija iz skeniranih dokumenata, PDF-a i slika, kako bih ih mogao urediti.
- Moram pretvoriti slike u pretraživ i uređiv tekstualni format.
- Tražim alat za pretvaranje mojih PDF dokumenata u uređujuće i pretražujuće formate.
- Imam problema u pretvaranju skeniranih dokumenata i slika u uređivani tekst.
Know a better solution? Let us know.
If you know of a tool or approach that could help people solve a problem we haven't covered yet, we'd love to hear about it.